TensorFlow with Horovod
TensorFlow is a software framework providing an API to express numerical computations using data flow graphs. It also provides an implementation to run those computations on a broad array of platforms, from mobile devices to large systems with heterogeneous environments. While usable in a variety of scientific domains, it is mainly intended for the development of machine-learning (ML) models, with a focus on deep neural networks. The development of TensorFlow was started internally at Google Inc., and the software was released as open source in November 2015.
Horovod is a framework developed by Uber Technologies Inc. to perform distributed training of deep neural networks on top of another ML framework, like TensorFlow, Keras, or PyTorch. Notably, it allows to replace TensorFlow's own parameter server architecture for distributed training with communications based on an MPI model, leveraging ring-allreduce algorithms for improved usability and performance.
Horovod 0.15.1 with CUDA 9.x
As test case, we select the tf_cnn_benchmark scripts from the Tensorflow project for benchmarking convolutional neural networks. We use a ResNet-50 model with a batch size of 64 and the synthetic image data which the benchmark scripts are able to generate autonomously. We performed runs from a minimum of 2 nodes up to 128 nodes, increasing the node count in powers of two.
Running the container
Assuming that the tensorflow-benchmark code is present in a directory which Sarus is
configured to automatically mount inside the container (here referred by the
arbitrary variable $INPUT), we can run the container application as follows:
srun -C gpu -N4 -t5 sarus run --mpi \
ethcscs/horovod:0.15.1-tf1.7.0-cuda9.0-mpich3.1.4-no-nccl \
python ${INPUT}/tensorflow-benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--model resnet50 --batch_size 64 --variable_update horovod
If the system administrator did not configure Sarus to mount the input data
location during container setup, we can use the --mount option:
srun -C gpu -N4 -t5 sarus run --mpi \
--mount=type=bind,src=<path-to-parent-directory>/tensorflow-benchmarks/scripts/,dst=/tf-scripts \
ethcscs/horovod:0.15.1-tf1.7.0-cuda9.0-mpich3.1.4-no-nccl \
python /tf-scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--model resnet50 --batch_size 64 --variable_update horovod
Native application
For the native implementation, we use TensorFlow 1.7.0, built using Cray Python
3.6, the Python extensions provided by the Cray Programming Environment 18.08,
CUDA 9.1 and cuDNN 7.1.4. These installations are performed by CSCS staff and
are available on Piz Daint through environment modules. We complete the software
stack by creating a virtual environment with Cray Python 3.6 and installing
Horovod 0.15.1 through the pip utility. The virtual environment is
automatically populated with system-installed packages from the loaded
environment modules.
Container image and Dockerfile
We start from the reference Dockerfile provided by Horovod for version 0.15.1
and modify it to use Python 3.5, TensorFlow 1.7.0, CUDA 9.0, cuDNN 7.0.5. These
specific versions of CUDA and cuDNN are required because they are the ones
against which the version of TensorFlow available through pip has been
built. We also replace OpenMPI with MPICH 3.1.4 and remove the installation of
OpenSSH, as the containers will be able to communicate between them thanks to
Slurm and the native MPI hook. Finally, we instruct Horovod not to use NVIDIA's
NCCL library for any MPI operation, because NCCL is not available natively on
Piz Daint.
The final Dockerfile
is the following:
1FROM nvidia/cuda:9.0-devel-ubuntu16.04
2
3# TensorFlow version is tightly coupled to CUDA and cuDNN so it should be selected carefully
4ENV HOROVOD_VERSION=0.15.1
5ENV TENSORFLOW_VERSION=1.7.0
6ENV PYTORCH_VERSION=0.4.1
7ENV CUDNN_VERSION=7.0.5.15-1+cuda9.0
8
9# NCCL_VERSION is set by NVIDIA parent image to "2.3.7"
10ENV NCCL_VERSION=2.3.7-1+cuda9.0
11
12# Python 2.7 or 3.5 is supported by Ubuntu Xenial out of the box
13ARG python=3.5
14ENV PYTHON_VERSION=${python}
15
16RUN apt-get update && apt-get install -y --no-install-recommends \
17 build-essential \
18 cmake \
19 git \
20 curl \
21 vim \
22 wget \
23 ca-certificates \
24 libcudnn7=${CUDNN_VERSION} \
25 libnccl2=${NCCL_VERSION} \
26 libnccl-dev=${NCCL_VERSION} \
27 libjpeg-dev \
28 libpng-dev \
29 python${PYTHON_VERSION} \
30 python${PYTHON_VERSION}-dev
31
32RUN ln -s /usr/bin/python${PYTHON_VERSION} /usr/bin/python
33
34RUN curl -O https://bootstrap.pypa.io/get-pip.py && \
35 python get-pip.py && \
36 rm get-pip.py
37
38# Install TensorFlow, Keras and PyTorch
39RUN pip install tensorflow-gpu==${TENSORFLOW_VERSION} keras h5py torch==${PYTORCH_VERSION} torchvision
40
41# Install MPICH 3.1.4
42RUN cd /tmp \
43 && wget -q http://www.mpich.org/static/downloads/3.1.4/mpich-3.1.4.tar.gz \
44 && tar xf mpich-3.1.4.tar.gz \
45 && cd mpich-3.1.4 \
46 && ./configure --disable-fortran --enable-fast=all,O3 --prefix=/usr \
47 && make -j$(nproc) \
48 && make install \
49 && ldconfig \
50 && cd .. \
51 && rm -rf mpich-3.1.4 mpich-3.1.4.tar.gz \
52 && cd /
53
54# Install Horovod, temporarily using CUDA stubs
55RUN ldconfig /usr/local/cuda-9.0/targets/x86_64-linux/lib/stubs && \
56 HOROVOD_WITH_TENSORFLOW=1 HOROVOD_WITH_PYTORCH=1 pip install --no-cache-dir horovod==${HOROVOD_VERSION} && \
57 ldconfig
58
59# Set default NCCL parameters
60RUN echo NCCL_DEBUG=INFO >> /etc/nccl.conf
61
62# Download examples
63RUN apt-get install -y --no-install-recommends subversion && \
64 svn checkout https://github.com/uber/horovod/trunk/examples && \
65 rm -rf /examples/.svn
66
67WORKDIR "/examples"
Used OCI hooks
NVIDIA Container Runtime hook
Native MPI hook (MPICH-based)
Results
We measure the performance in images/sec as reported by the application logs and compute speedup values using the performance averages for each data point, taking the native performance at 2 nodes as baseline. The results are showcased in the following Figure:
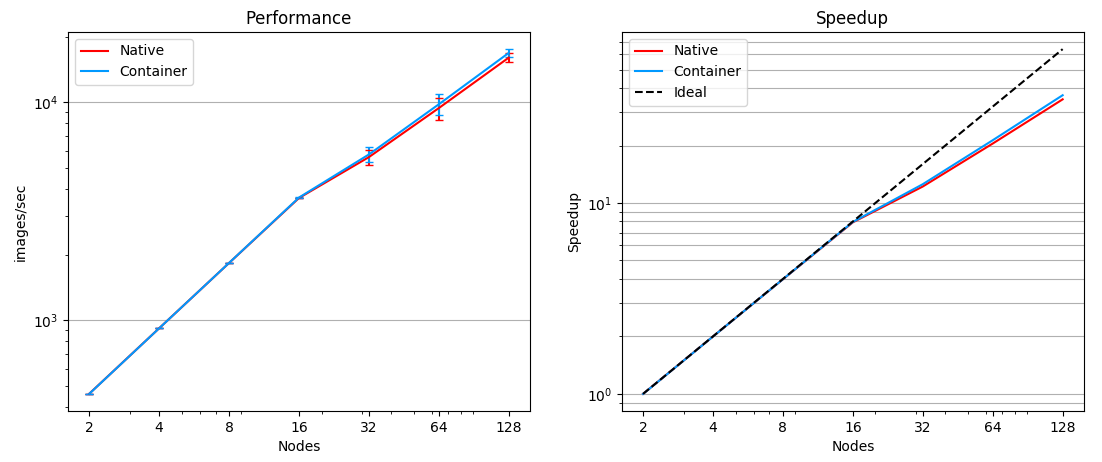
Comparison of performance and speedup between native and Sarus-deployed container versions of TensorFlow with Horovod on Piz Daint.
We observe the container application closely matching the native installation when running on up to 16 nodes, with performance differences and normalized standard deviations less than 0.5%. From 32 nodes upwards, the container application shows a small performance advantage, up to 5% at 128 nodes, with both implementations maintaining close standard deviation values.
Horovod 0.16.x with CUDA 10.0
In this test case, we select again the tf_cnn_benchmark scripts from the Tensorflow project but now we test all four different models that the benchmark supports, namely the alexnet, inception3, resnet50 and vgg16. The batch size is again 64 and for each of the models we use a node range of 1 to 12 nodes.
Running the container
If the tensorflow-benchmark code is present in a directory which Sarus is
configured to automatically mount inside the container (here referred by the
arbitrary variable $INPUT), we can run the container application as follows:
srun -C gpu -N4 sarus run --mpi \
ethcscs/horovod:0.16.1-tf1.13.1-cuda10.0-mpich3.1.4-nccl \
python ${INPUT}/tensorflow-benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--model resnet50 --batch_size 64 --variable_update horovod
Alternatively, the --mount option can be used:
srun -C gpu -N4 -t5 sarus run --mpi \
--mount=type=bind,src=<path-to-parent-directory>/tensorflow-benchmarks/scripts/,dst=/tf-scripts \
ethcscs/horovod:0.16.1-tf1.13.1-cuda10.0-mpich3.1.4-nccl \
python /tf-scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--model resnet50 --batch_size 64 --variable_update horovod
The above commands are using the resnet50 model. Using the --model
option it is possible to run the benchmarks with the other models as well.
Native application
For the native implementation, we use Horovod 0.16.0 with TensorFlow 1.12.0, built using Cray Python 3.6, the Python extensions provided by the Cray Programming Environment 19.03, CUDA 10.0, cuDNN 7.5.6 and NCCL 2.4.2. These installations are performed by CSCS staff and are available on Piz Daint through environment modules.
Container image and Dockerfile
We start from the reference Dockerfile provided by Horovod for version 0.16.1
and modify it to use Python 3.5, TensorFlow 1.13.1, CUDA 10.0, cuDNN 7.5.0. and
NCCL 2.4.2. These specific versions of CUDA and cuDNN are required because they
are the ones against which the version of TensorFlow available through pip
has been built. We also replace OpenMPI with MPICH 3.1.4. and remove the
installation of OpenSSH, as the containers will be able to communicate thanks to
Slurm and the native MPI hook Finally, we instruct Horovod to use NVIDIA's NCCL
library for every MPI operation by adding the appropriate environment variables
to the /etc/nccl.conf configuration file.
The resulting Dockerfile
is the following:
1FROM nvidia/cuda:10.0-devel-ubuntu16.04
2
3# Define the software versions
4ENV HOROVOD_VERSION=0.16.1 \
5 TENSORFLOW_VERSION=1.13.1 \
6 CUDNN_VERSION=7.5.0.56-1+cuda10.0 \
7 NCCL_VERSION=2.4.2-1+cuda10.0
8
9# Python version
10ARG python=3.5
11ENV PYTHON_VERSION=${python}
12
13# Install the necessary packages
14RUN apt-get update && \
15 apt-get install -y --no-install-recommends \
16 cmake git curl vim wget ca-certificates \
17 libibverbs-dev \
18 libcudnn7=${CUDNN_VERSION} \
19 libnccl2=${NCCL_VERSION} \
20 libnccl-dev=${NCCL_VERSION} \
21 libjpeg-dev \
22 libpng-dev \
23 python${PYTHON_VERSION} python${PYTHON_VERSION}-dev
24
25# Create symbolic link in order to make the installed python default
26RUN ln -s /usr/bin/python${PYTHON_VERSION} /usr/bin/python
27
28# Download pip bootstrap script and install pip
29RUN curl -O https://bootstrap.pypa.io/get-pip.py && \
30 python get-pip.py && \
31r m get-pip.py
32
33# Install Tensorflow, Keras and h5py
34RUN pip install tensorflow-gpu==${TENSORFLOW_VERSION} keras h5py
35
36# Install MPICH 3.1.4
37RUN cd /tmp \
38 && wget -q http://www.mpich.org/static/downloads/3.1.4/mpich-3.1.4.tar.gz \
39 && tar xf mpich-3.1.4.tar.gz \
40 && cd mpich-3.1.4 \
41 && ./configure --disable-fortran --enable-fast=all,O3 --prefix=/usr \
42 && make -j$(nproc) \
43 && make install \
44 && ldconfig \
45 && cd .. \
46 && rm -rf mpich-3.1.4 mpich-3.1.4.tar.gz \
47 && cd /
48
49# Install Horovod
50RUN ldconfig /usr/local/cuda-10.0/targets/x86_64-linux/lib/stubs && \
51 HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_WITH_TENSORFLOW=1 pip install --no-cache-dir horovod==${HOROVOD_VERSION} && \
52l dconfig
53
54# NCCL configuration
55RUN echo NCCL_DEBUG=INFO >> /etc/nccl.conf && \
56 echo NCCL_IB_HCA=ipogif0 >> /etc/nccl.conf && \
57 echo NCCL_IB_CUDA_SUPPORT=1 >> /etc/nccl.conf
Used OCI hooks
NVIDIA Container Runtime hook
Native MPI hook (MPICH-based)
Results
We measure the performance in images/sec as reported by the application logs by taking the mean value based on 5 different runs for each model and node number. The results are showcased in the following Figure:
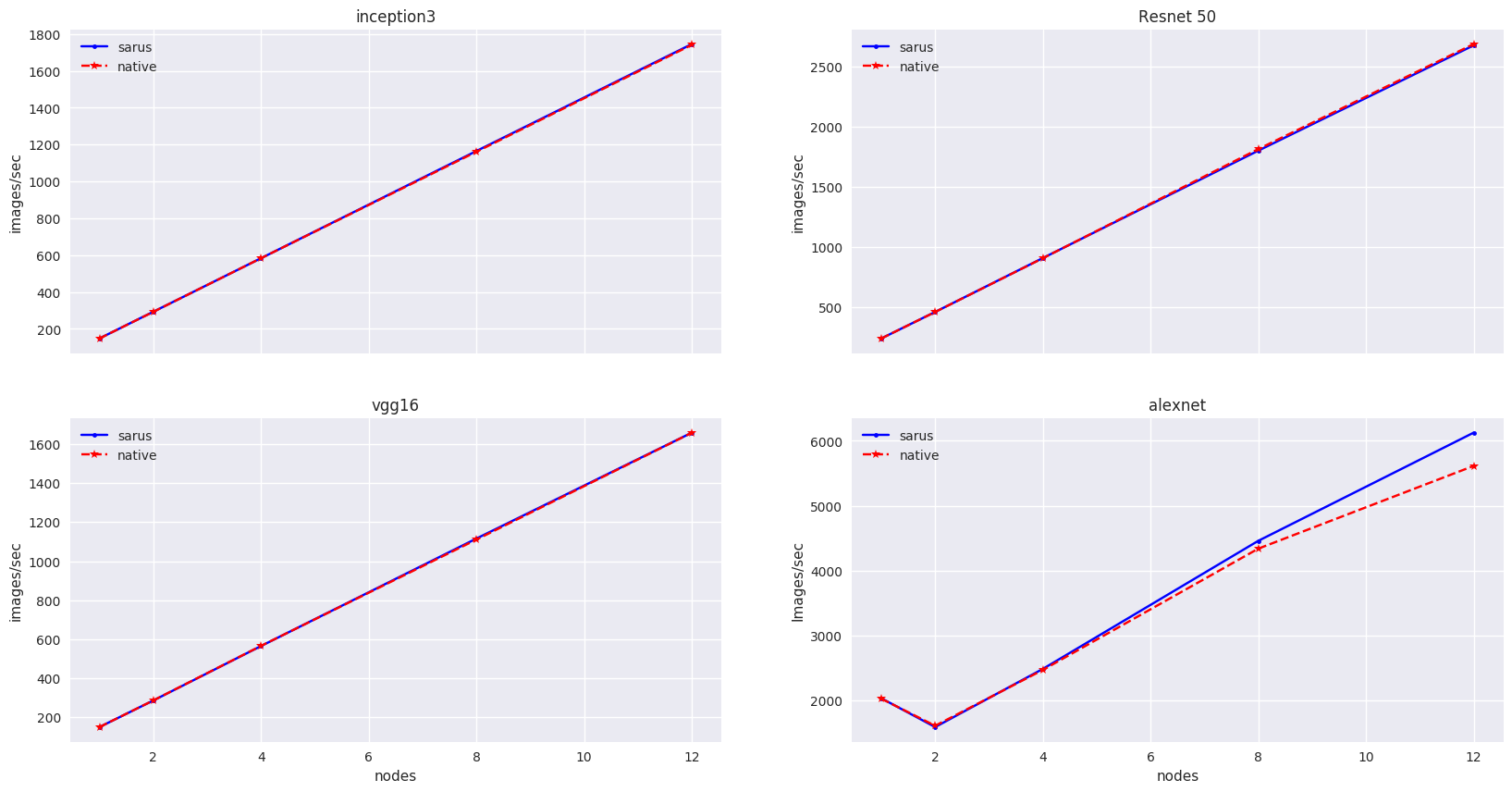
Comparison of performance between native and Sarus-deployed container versions of TensorFlow with Horovod on Piz Daint.
We observe that performance of the container-based horovod-tensorflow is identical to the native one. An slight increased performance of the containized solution is observed only for the alexnet model as the number of nodes increases.